
The statement is ultimately false, but a single update query will cause the table's size to increase. This occurs due to PostgreSQL's storage model and its use of MVCC (Multi-Version Concurrency Control). To fully explain this, we must first understand these two concepts.
PostgreSQL's storage model
PostgreSQL stores all database objects (e.g., table rows, index records) in files. These files are divided into fixed-size blocks, called pages, which are each 8 KB.

Figure 1 shows the page structure, which consists of five main parts:
1. PageHeaderData: 24 bytes long, contain general information about the page.
- ItemIdData: Array of item identifiers pointing to actual item. Each entry is an (offset, size) pair, 4 bytes per item
- Free Space: The unallocated space, new item identifiers are allocated from the start of this area, new items from the end.
- Items: the actual items themselves
- Special Space: index access method specific data, Different methods store different data, empty is ordinary tables.
Now its time to explain MVCC (Multi-Version Concurrency Control)
MVCC (Multi-Version Concurrency Control)
MVCC is a database concurrency control method that allows multiple transactions to access the same data simultaneously without blocking each other, while maintaining data consistency.
As the name suggests, PostgreSQL duplicates the database for each query

Just kidding! 😂 The reality is actually more complex. To truly understand how MVCC works, we need to start with two fundamental concepts:
- Transaction ID
- Tuple Structure
Let's deep-dive into how these pieces fit together.
Transaction ID:
Each transaction has an id which is a 32-byte-long number that increments over the time.
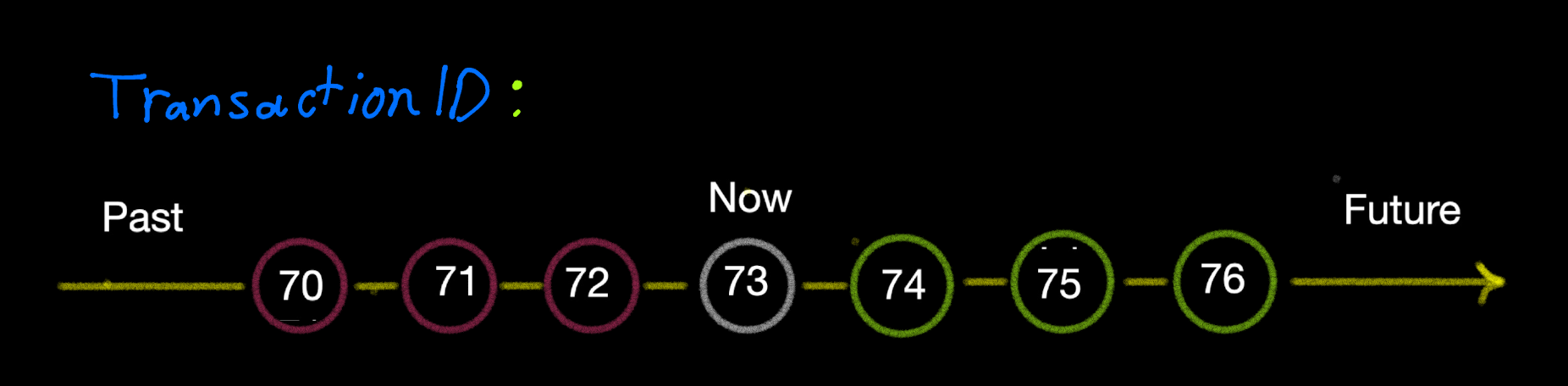
To get the current transaction id, just execute the following command:
SELECT txid_current()Tuple structure

Figure 3 shows the structure of a single tuple, which consists of two main parts:
- User Data: The actual data stored in the tuple.
- HeapTupleHeaderData: Additional metadata that the database needs to operate.
The HeapTupleHeaderData contains several fields, but we will focus on only two of them for this section:
- t_xmin: Holds the transaction ID that inserted this tuple.
- t_xmax: Holds the transaction ID that updated or deleted this tuple.
Now, let's look at an example to demonstrate how these two fields are populated.
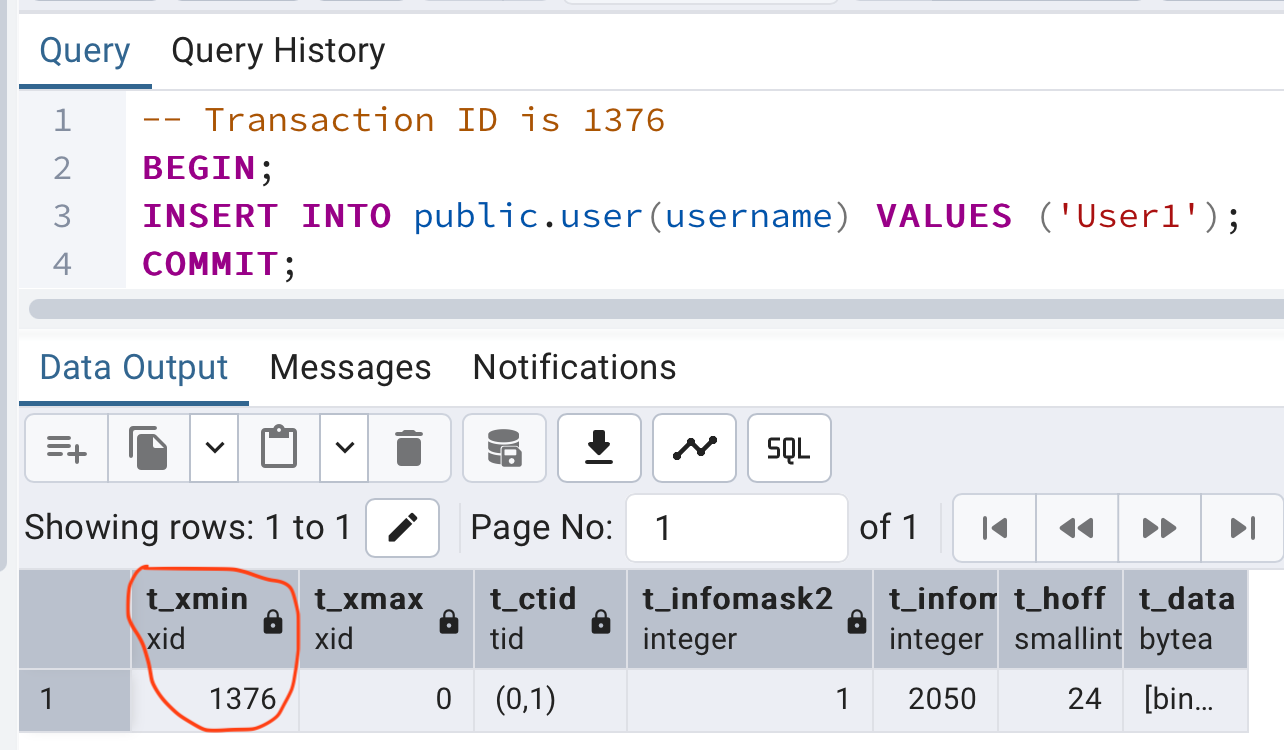
Insert query
During insertion, a new tuple is inserted into a page. This tuple's t_xmin field is filled with the current transaction ID, and its t_xmax field is set to zero (which means it is not deleted).
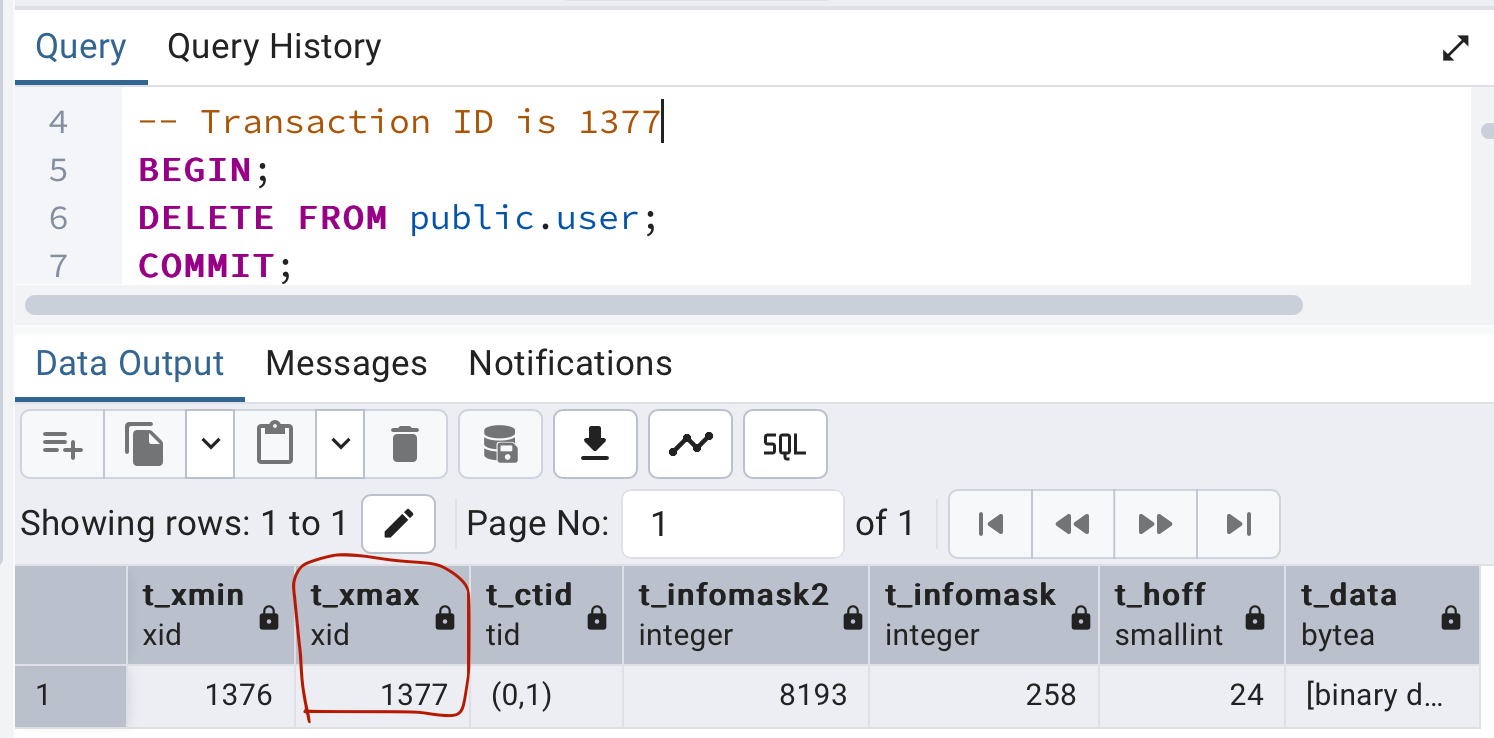
Delete query
The deletion of a tuple is handled by setting its t_xmax field to the transaction ID of the deleting transaction, and this tuple is then called a dead tuple.
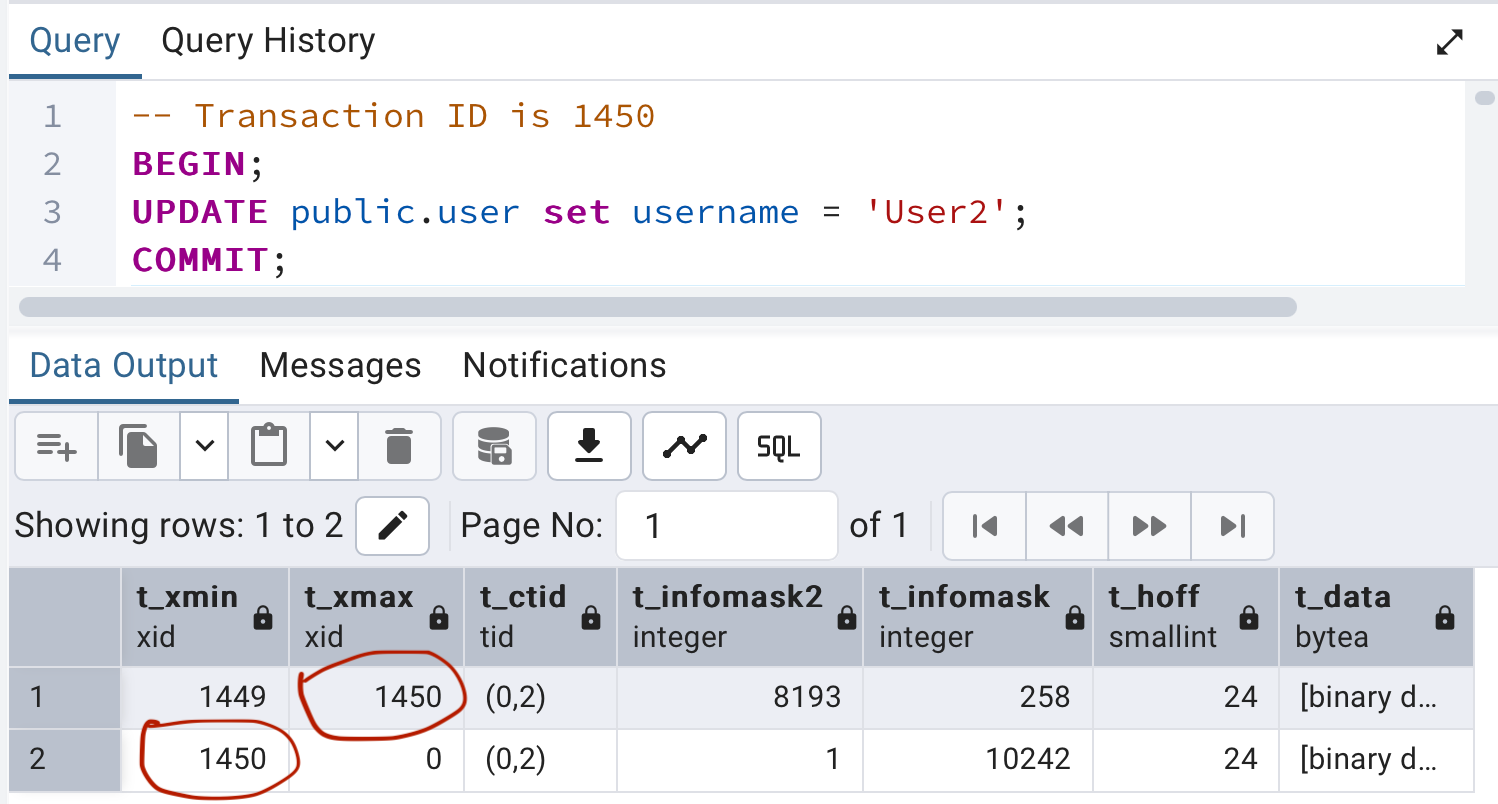
Update query
An UPDATE operation functions internally as a combination of a DELETE and an INSERT. The original tuple is marked as deleted, and a new version of the tuple is created. This mechanism results in two physical versions of the same logical record existing simultaneously in the database.
Therefore, UPDATE operations increase table size due to the creation of dead tuples. This effect is temporary until vacuuming occurs. To force a cleanup and reclaim space, use the command:
VACUUM FULL table_name;